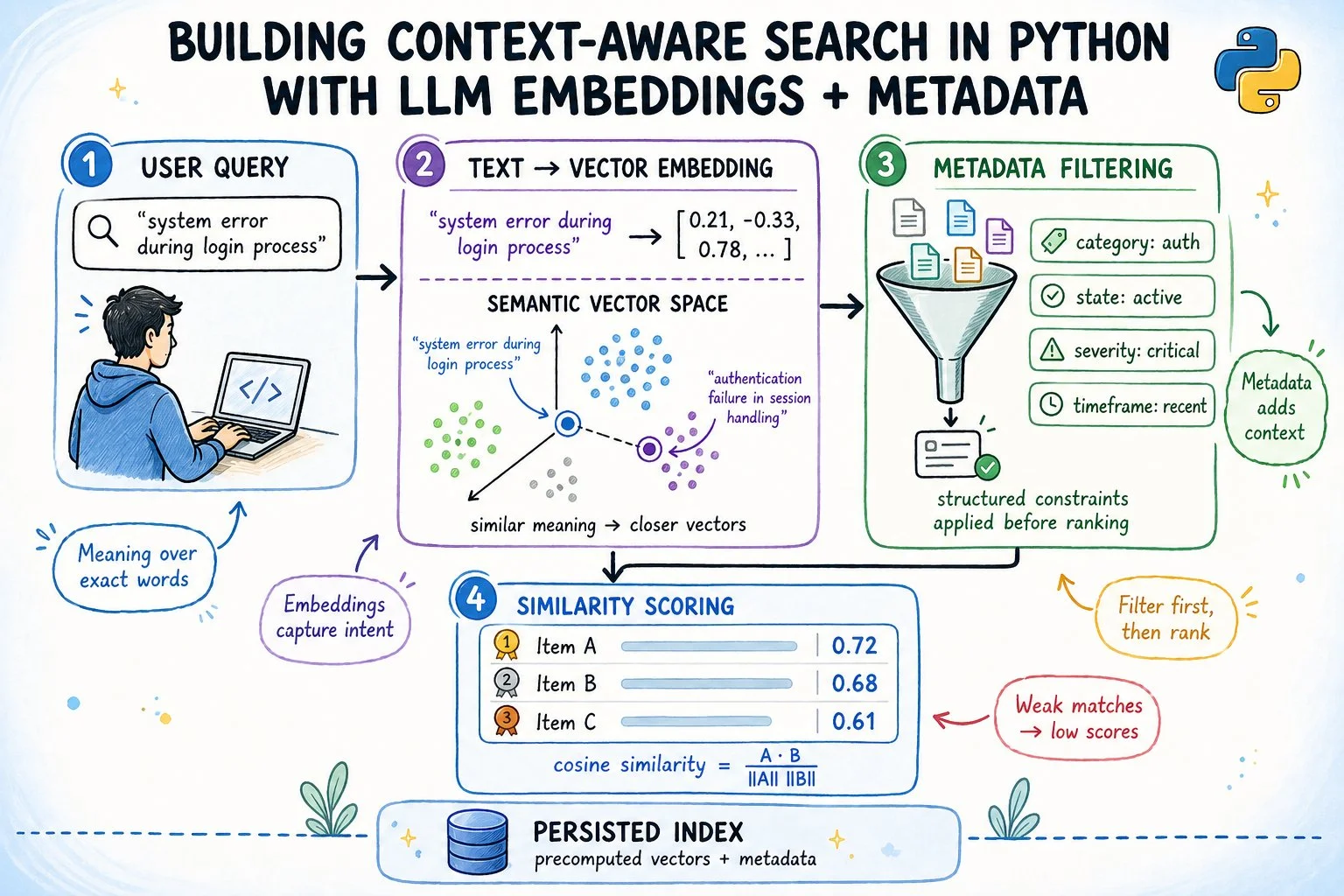
Традиційний пошук за ключовими словами часто зазнає краху, як тільки користувач вводить запит. Наприклад, інженер підтримки, який шукає «login keeps failing», не знайде тікет з назвою «OAuth2 token refresh race condition», хоча це саме те, що йому потрібно. Ця проблема є основою, яку вирішує контекстно-залежний семантичний пошук. Семантичний пошук перетворює текст на щільні векторні представлення, відомі як ембединги. У цьому високорозмірному просторі близькість визначається змістом, а не точним збігом слів.
Для підвищення точності до цього процесу додають структуровані фільтри метаданих — за датою, статусом, командою чи пріоритетом. Це створює систему, яка розуміє що запитує користувач, одночасно поважаючи контекстуальні обмеження. У цій статті детально розглядається побудова такої системи: від генерації ембедингів за допомогою локальної попередньо навченої моделі до індексу, що зберігається на диску та підтримує фільтрацію метаданими.
Як працює семантичний пошук?
Модель ембедингу речення приймає текстовий рядок і повертає вектор фіксованої довжини з чисел із плаваючою комою. Модель навчається таким чином, що речення зі схожим змістом генерують вектори, які вказують у схожих напрямках у високорозмірному просторі. Косинусна подібність вимірює кут між двома векторами: $\text{cosine similarity}(A, B) = \frac{A \cdot B}{\|A\| \|B\|}$. Якщо вектори нормалізовані до одиниці (тобто їхня довжина дорівнює 1.0), це спрощується до скалярного добутку: $A \cdot B$. Оцінки варіюються від -1 (протилежні) до 1 (ідентичні). На практиці непов'язані документи отримують оцінку близько 0.1–0.25, а сильні збіги — вище 0.6.
Чому важлива фільтрація метаданих?
Хоча моделі ембедингів ефективно кодують семантичний зміст, вони не містять інформації про те, хто написав документ, яка команда ним володіє чи коли він був створений. Ці атрибути існують поза текстом і повинні оброблятися окремо. Комбінування обох сигналів — семантичного балу та обмежень метаданих — робить пошук корисним у реальних системах.
Етапи побудови контекстно-залежного індексу
Для демонстрації концепції використовується корпус із 20 тікетів технічної підтримки, розподілених між трьома командами: infrastructure, backend та frontend. Кожен тікет є простим словником; поле `text` піддається ембедингу, а все інше служить метаданими для фільтрації.
- Генерація локальних ембедингів: Використовується попередньо навчена модель, що дозволяє генерувати 384-вимірні ембединги без необхідності використання API ключів.
- Індексація з фільтрацією: Створюється пошуковий індекс, який застосовує фільтри за командою, статусом, пріоритетом та датою до оцінювання кандидатів.
- Ранжування на основі косинусної подібності: Після відфільтровування вузького пулу кандидатів відбувається ранжування їхньої релевантності за допомогою косинусної подібності.
- Збереження індексу: Інтерфейс дозволяє зберігати індекс на диску, що гарантує, що ембединги обчислюються лише один раз і ефективно перезавантажуються при наступних запусках системи.
Перспективи
Побудова такого контекстно-залежного пошуку є важливим кроком у розвитку систем підтримки та аналітики даних. Це переводить пошук із пасивного збігу слів у активне розуміння наміру користувача, що критично важливо для великих корпоративних систем і AI-застосунків.