За даними Medicalxpress, нещодавнє дослідження під керівництвом вчених Penn State проаналізувало якість медичних відповідей, згенерованих штучним інтелектом. Мета цього вивчення полягала у визначенні точності та потенційної шкідливості інформації, яку надають чат-боти на тему здоров'я для середнього користувача інтернету. Для проведення дослідження було організовано конкурс «Diagnose-a-thon» в Penn State.
Методологія оцінки AI у сфері охорони здоров’я
У рамках конкурсу взяли участь 34 учасники — викладачі, співробітники та студенти. Вони подали загалом 212 промптів і відповідних на них згенерованих AI-текстів щодо реальних та уявних медичних проблем, які були написані як від імені пацієнта, так і від імені лікаря. Учасникам було дозволено обирати одну з чотирьох великих мовних моделей: ChatGPT-4o, ChatGPT-3.5, Gemini-1.5 Pro та Llama3-8b.
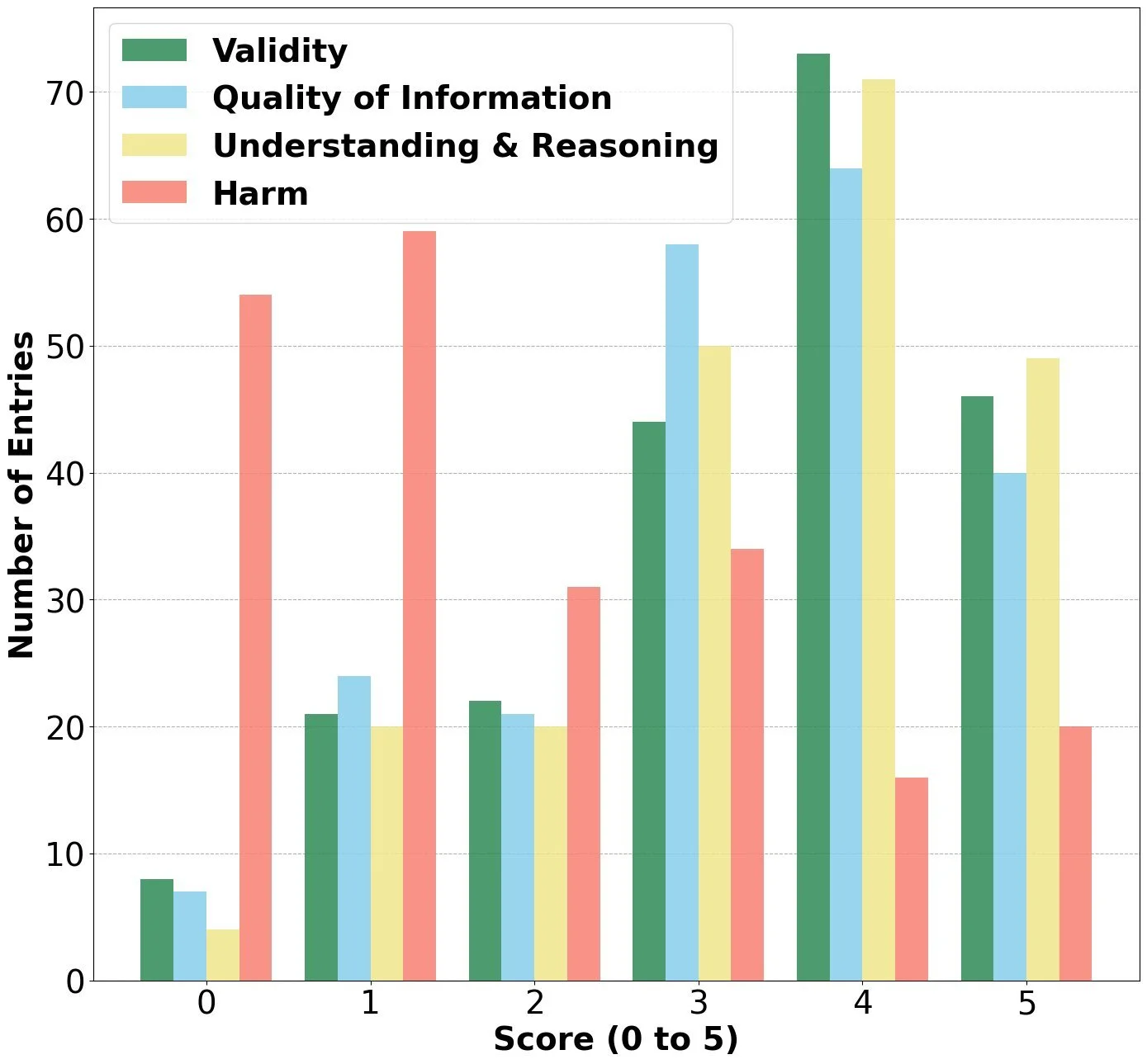
Як зазначив Bonam Mingole, головний автор дослідження і докторант у галузі інформаційних наук, «одна з переваг нашого вивчення полягає в тому, що ми фактично намагаємося відтворити реальне використання LLM, просячи учасників обирати модель, яку вони б використали у звичайний день». Після генерації відповідей їх оцінили дев'ять лікарів із сертифікацією. Лікарі використовували шестибальну шкалу для визначення точності та потенційної шкідливості наданої інформації.
Спеціалізовані відмінності у якості AI-відповідей
Загальна точність відповідей LLM становила 76.2%. Однак дослідження виявило значні відмінності залежно від медичної спеціалізації. Найкращі результати продемонстрували такі галузі, як акушерство та гінекологія, а також отоларингологія — лікування розладів, що впливають на вухо, ніс і горло. Ці спеціальності показали високі показники валідності при низьких оцінках шкідливості.
- Найкраща продуктивність: Акушерство та гінекологія; Отоларингологія.
- Найгірша продуктивність: Внутрішня медицина, неврологія та дерматологія.
Дослідники відзначили, що в галузях внутрішньої медицини, неврології та дерматології AI показав найменші показники валідності при вищих оцінках ризику для пацієнта. Це підкреслює критичну необхідність обережності при використанні цих інструментів у складних діагностичних ситуаціях. Дослідники додали, що дуже специфічні запити та промпти між 60 і [далі йде текст джерела] є ключовими для підвищення якості відповідей.
Висновок
Результати цього дослідження підтверджують необхідність обережного ставлення до медичних порад, наданих штучним інтелектом. Хоча LLM можуть бути корисними для загальної інформації, їхня нерівномірна точність у вузьких спеціальностях вимагає постійного моніторингу та подальших клінічних досліджень.